















無料で利用できる実質エクセル的なスプレッドシート。とりあえず利便性が高すぎる。
今回はスプレッドシートで佐川急便の配達状況をトラッキングできる仕様を適当に構築する。
はじめに
API叩いたりGAS使えば解決だろとか言う😡
佐川急便からスマートAPIが提供されているものの、基本はEC事業者向け。利用申請(問い合わせ)も必要で、利用規約を確認した限り料金もかかりそう。GAS(Google Apps Script)は素人だと取っつきにくい。なら簡単な関数を使って個人でそれっぽい仕様を構築しちゃえばいいじゃんってこと。
だがそもそもの話だが、佐川急便に登録しておけば配達予定通知だとか配達完了通知はメールで受け取れるようになっている(発送元/受け取り側いずれも)。
じゃあこんなの作っても特に意味なくねと思われるかもしれないが、その通り。
特に意味はない。自己満足の領域。強いて理由をあとづけするとすれば、IMPORTXML関数の使い方を調べている方の役に立てばいいな程度。でもこんなのちょっと調べればすぐ出てくるしやはり蛇足か。
佐川急便のお荷物問い合わせサービス

https://k2k.sagawa-exp.co.jp/p/web/okurijosearch.do?oku01=
上記URLの末尾にお問い合わせ番号(=追跡番号=12桁)を入力すると、追跡番号の荷物の配達状況が確認できる。今回はお試しで123456789012という架空の追跡番号を入力。
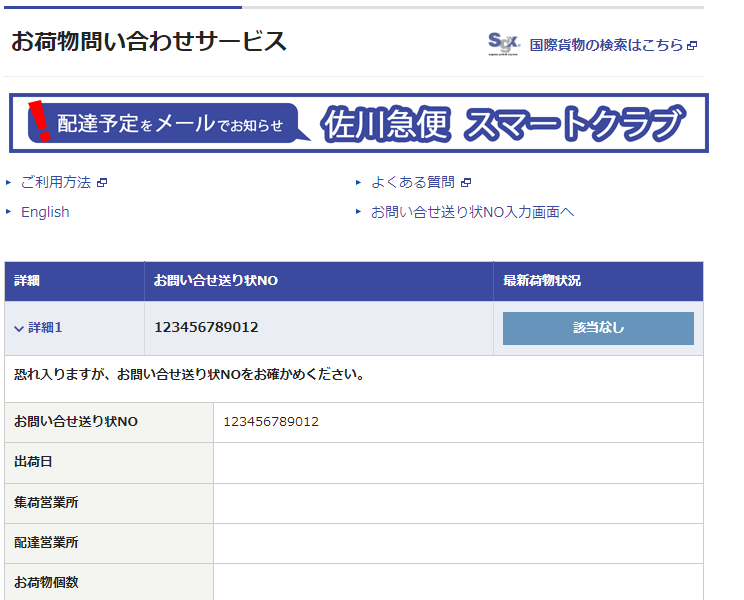
するとこのように表示された。
当該の追跡番号は架空の番号で、実際に使われていない番号のため出荷日時の表示もなく、最新荷物状況についても当該なしとなっている。
次に、実際に使われている番号を入力してみる。
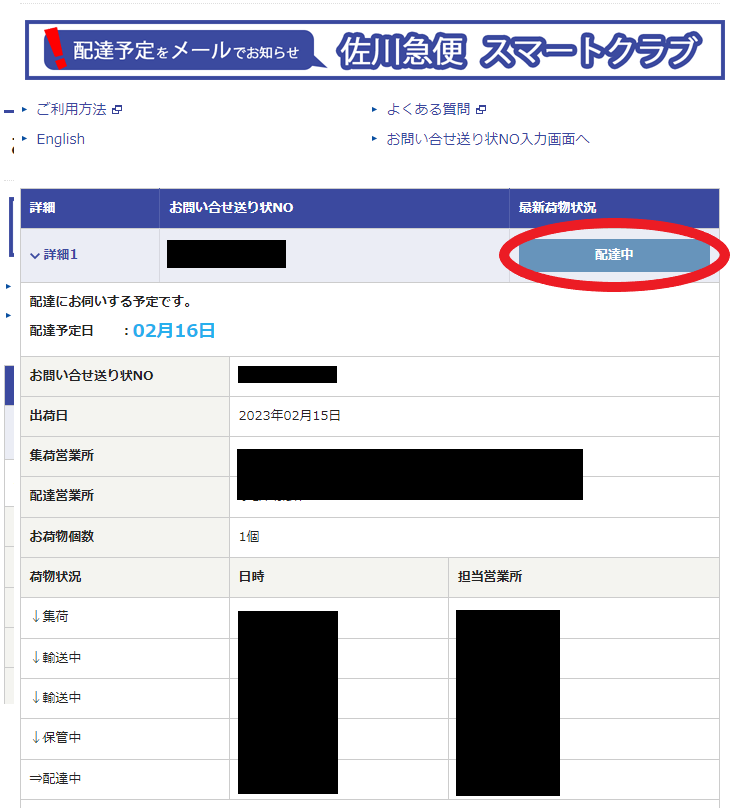
塗りつぶしている箇所が多くて申し訳ないが、塗りつぶし箇所は全て場所や日時、追跡番号が表示されている。
また右上の最新荷物状況についても、配達中となっている。この最新荷物状況については状況が更新され次第逐一更新される。そのため、この最新荷物状況をスプレッドシート側で取得すれば配達状況が確認できる。
スプレッドシートの下準備
スプレッドシートの準備

とりあえずGoogleアカウントにログインして、スプレッドシートを準備。どんなシートでもいいが、今回は分かりやすいようにまっさらなシートを用意した。
お次に適当な場所へ、適当な内容を入力。
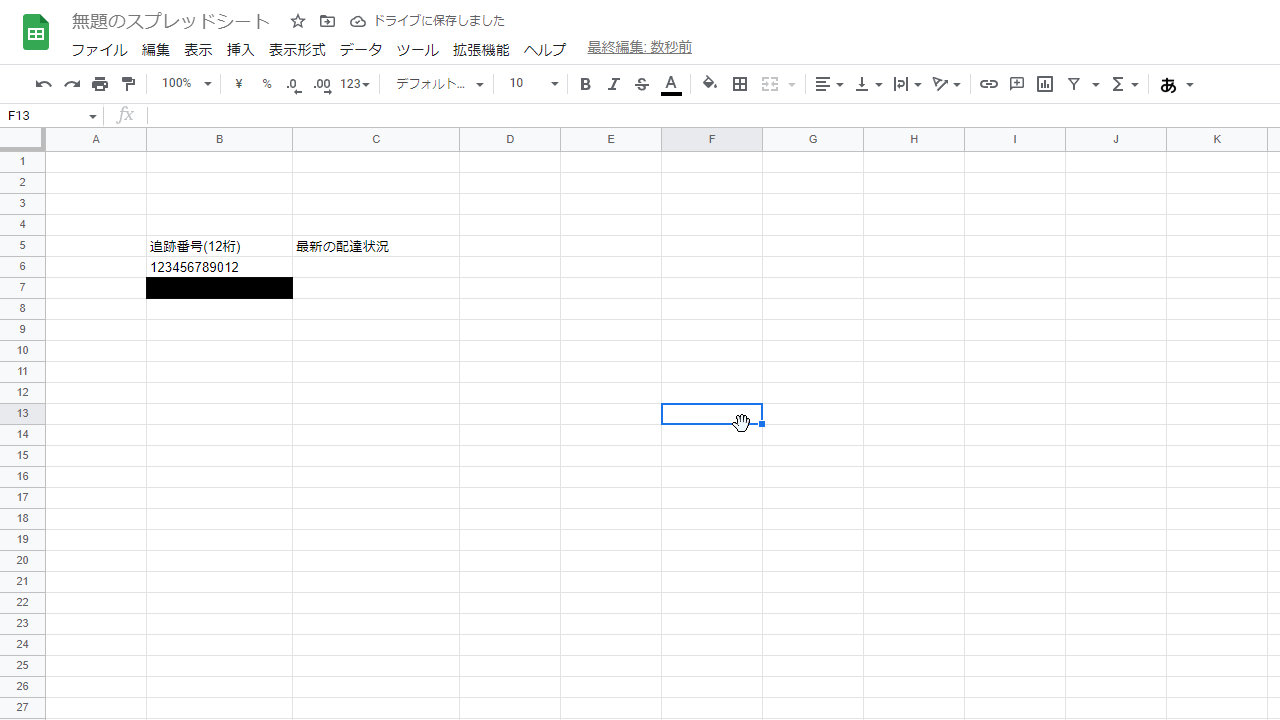
今回はB5セルに追跡番号(12桁)と入力し、以下の列には追跡番号を入力していく形式にした。
※B7セルが真っ黒ですが、実際に使用された追跡番号を入力しています。黒色塗りつぶしで真っ黒になっているだけです。
C5セルに最新の配達状況と入力し、以下の列には左のB列に入力されている追跡番号に応じて配達状況を表示させる(ここが本題)。
そしてとりい出したるはIMPORTXML関数。
IMPORTXML関数

IMPORTHTML
HTML ページ内の表やリストからデータをインポートします。使用例
IMPORTHTML(“http://en.wikipedia.org/wiki/Demographics_of_India”,”table”,4)
IMPORTHTML(A2,B2,C2)~中略~
google IMPORTHTMLのサポートページより引用
IMPORTXML: XML、HTML、CSV、TSV、RSS フィード、Atom XML フィードなど、さまざまな種類の構造化データからデータをインポートします。
は?
外資系企業特有の全然サポートになっていないサポートページやめろ。分かりづらすぎるぞ。
面倒な説明はガッツリ省略。IMPORTXMLは、表示されているページ上の特定の箇所に存在するデータをインポート(読み込む)という関数。
今回は先程のページの、
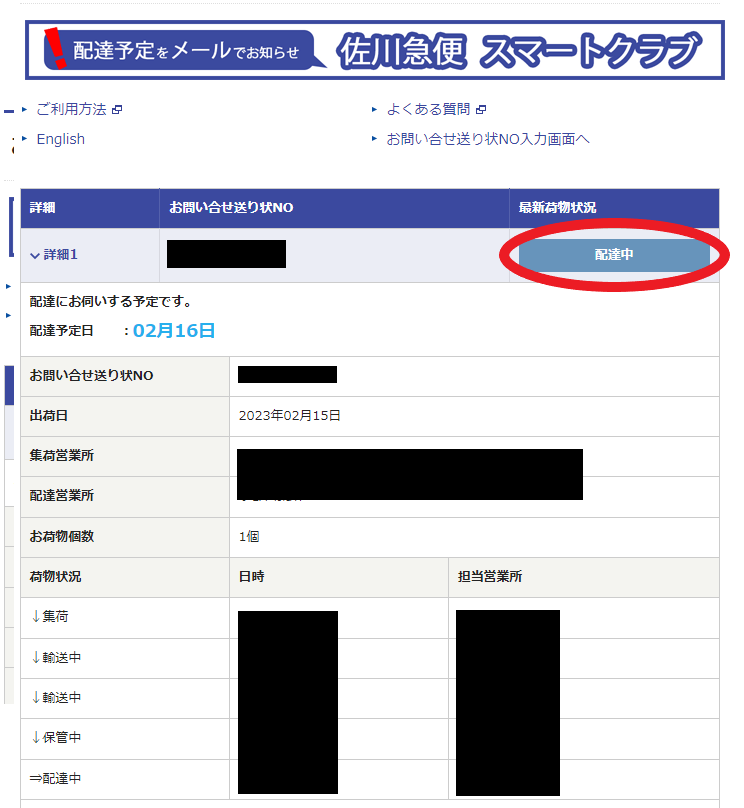
この赤丸部分の文字(最新荷物状況)をスプレッドシートにインポートしてやろうということ。
IMPORTXMLの使い方
=IMPORTXML(“任意のURL”,”任意のXPath”)
これでデータの読み込みができる。
※カッコ内のダブルクォーテーションマーク→””も必要。全角はダメ。半角でね。カッコも半角。
いくらなんでもこの説明だと何がなんやらなので、もう少し噛み砕く。
任意のURL
ここは余談程度なので飛ばしても構わないのだが、この次に説明する任意のXPathの項目は一応目を通しておいて欲しい。
手始めにYahooトップのニュース、上位3つを抽出してみる。
まず抽出したいページのURLはご存知Yahooトップのページなので、https://www.yahoo.co.jp/。この時点で=IMPORTXML(“https://www.yahoo.co.jp/”,までは埋まった。
任意のXPath
抽出したいデータのXPathを探すのだが、探し方は本題に戻った時点で詳しく紹介する。
ここでは既に特定済みのXPathをスプレッドシートに記入した。
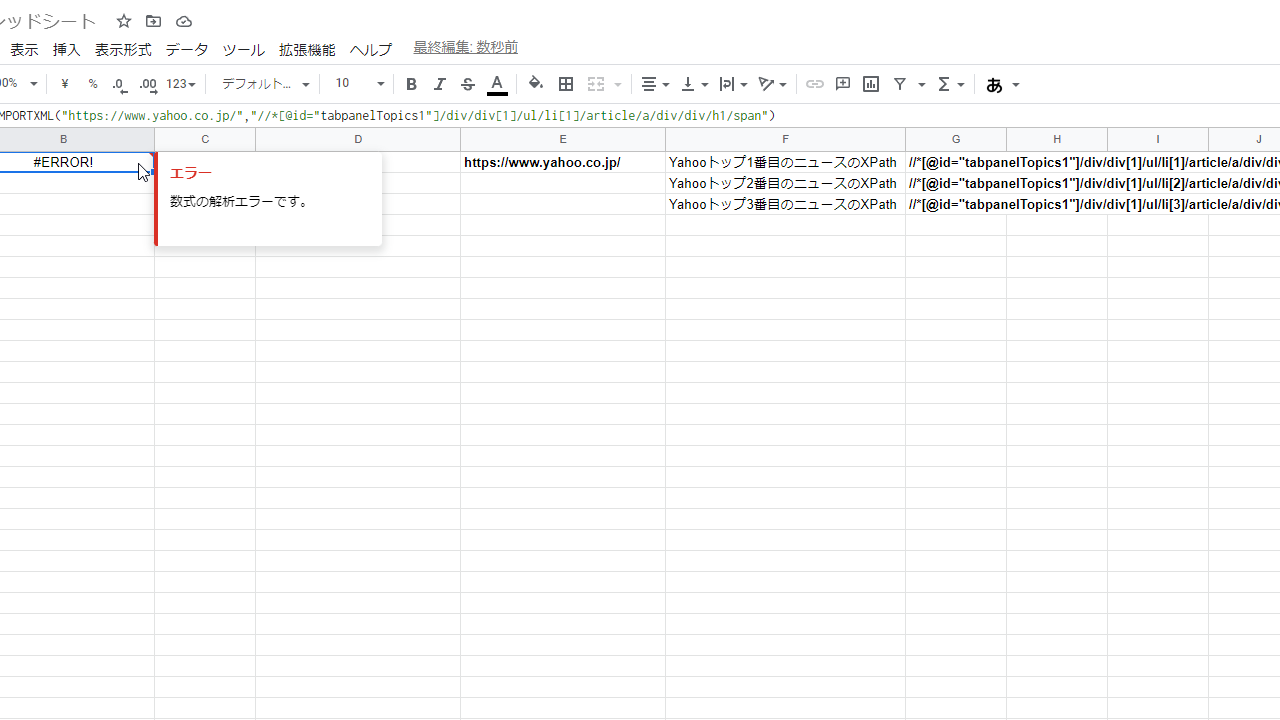
分かりやすくするため、E1セルにYahooトップのURL、G1:G3セルに、Yahooトップニュースの1番目:3番目までのXPathを記入した。
正直不要だとは思われるが、一応各XPathを書いておく。 //*[@id="tabpanelTopics1"]/div/div[1]/ul/li[1]/article/a/div/div/h1/span //*[@id="tabpanelTopics1"]/div/div[1]/ul/li[2]/article/a/div/div/h1/span //*[@id="tabpanelTopics1"]/div/div[1]/ul/li[3]/article/a/div/div/h1/span 上から順に、Yahooトップのニュースの1番目、2番目、3番めのXPath。
=IMPORTXML(“任意のURL”,”任意のXPath”)の型に各種情報を当てはめると、
=IMPORTXML("https://www.yahoo.co.jp/","//*[@id="tabpanelTopics1"]/div/div[1]/ul/li[1]/article/a/div/div/h1/span")となる。
※改行しているように見えるがサイトの仕様上改行しているように見えるだけ。実際は改行していないので注意。
これで準備よし。いざ読み込み…!!
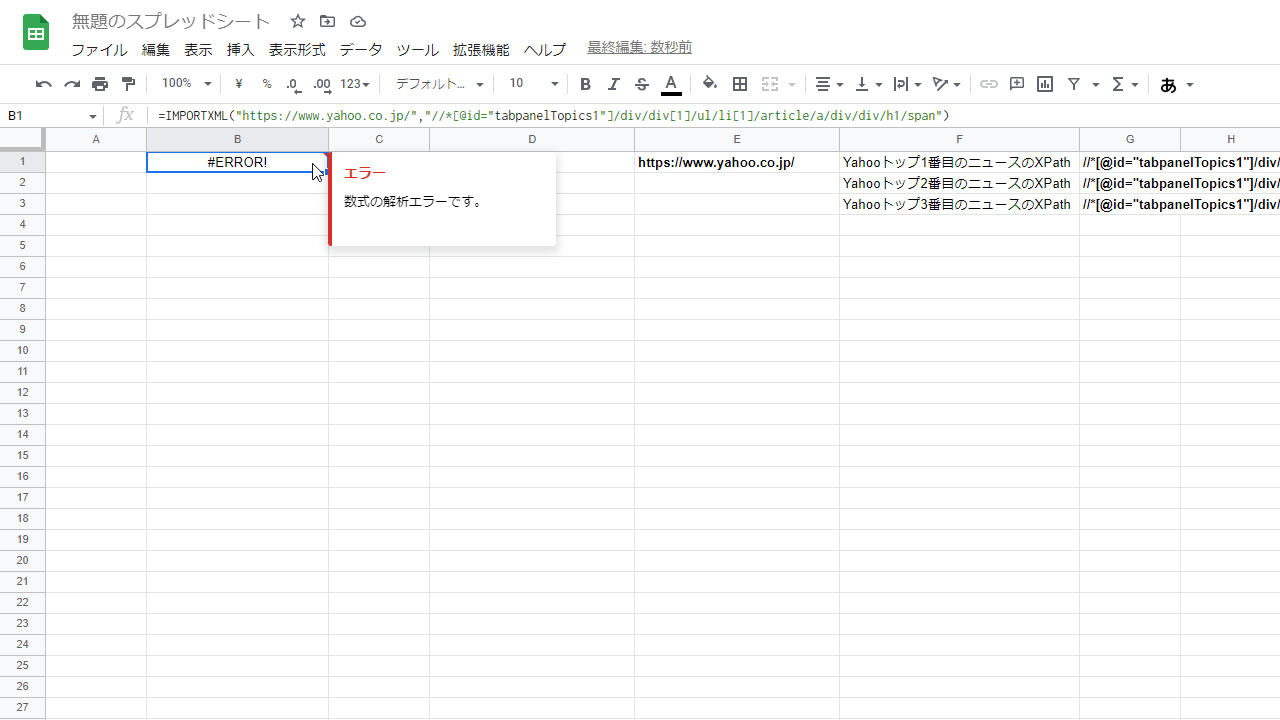
は?
ここで言い忘れていたことがあるのだが、肝となる部分はまだある。
先程のXPathをご覧頂くと、XPath内部にダブルクォーテーション(“”)が使われている。
//*[@id="tabpanelTopics1"]/div/div[1]/ul/li[1]/article/a/div/div/h1/sp
これがIMPORTXML関数のダブルクォーテーションに干渉しているためエラーを吐く。
仮にXPath内にダブルクォーテーションが使われている場合は、XPath側のダブルクォーテーションをシングルクォーテーションに変更してやることで解決する。
変更前
//*[@id="tabpanelTopics1"]/div/div[1]/ul/li[1]/article/a/div/div/h1/sp
変更後
//*[@id='tabpanelTopics1']/div/div[1]/ul/li[1]/article/a/div/div/h1/sp
最終的な表記
=IMPORTXML("https://www.yahoo.co.jp/","//*[@id='tabpanelTopics1']/div/div[1]/ul/li[1]/article/a/div/div/h1/span")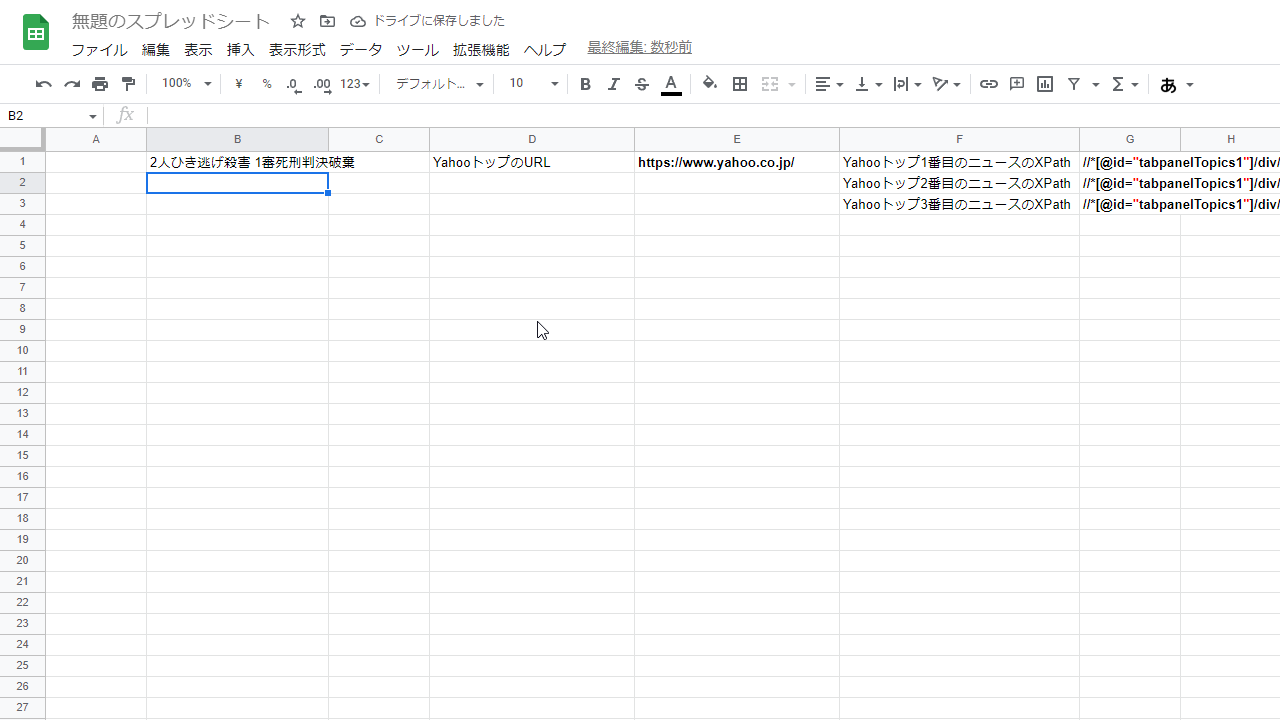
するとこのように、トップページ一番上のニュースのデータがテキストで抽出された。
(なんか物騒なニュースだな…)
なおいちいちURLを入力するのが面倒な場合は、URLやXPathを別のセルに入力しておき、そのセルを指定してやることでも問題ない。
今度は上から2番目のニュースを読み込みたいとする。
E1セルにYahooトップのURLを記入しているため、=IMPORTXML(E1,となる。そして上から2番目のニュースのXPathはG2セルにあるため、=IMPORTXML(E1,G2)となる。
※セルを指定する形式の場合、ダブルクォーテーションは不要。
すると
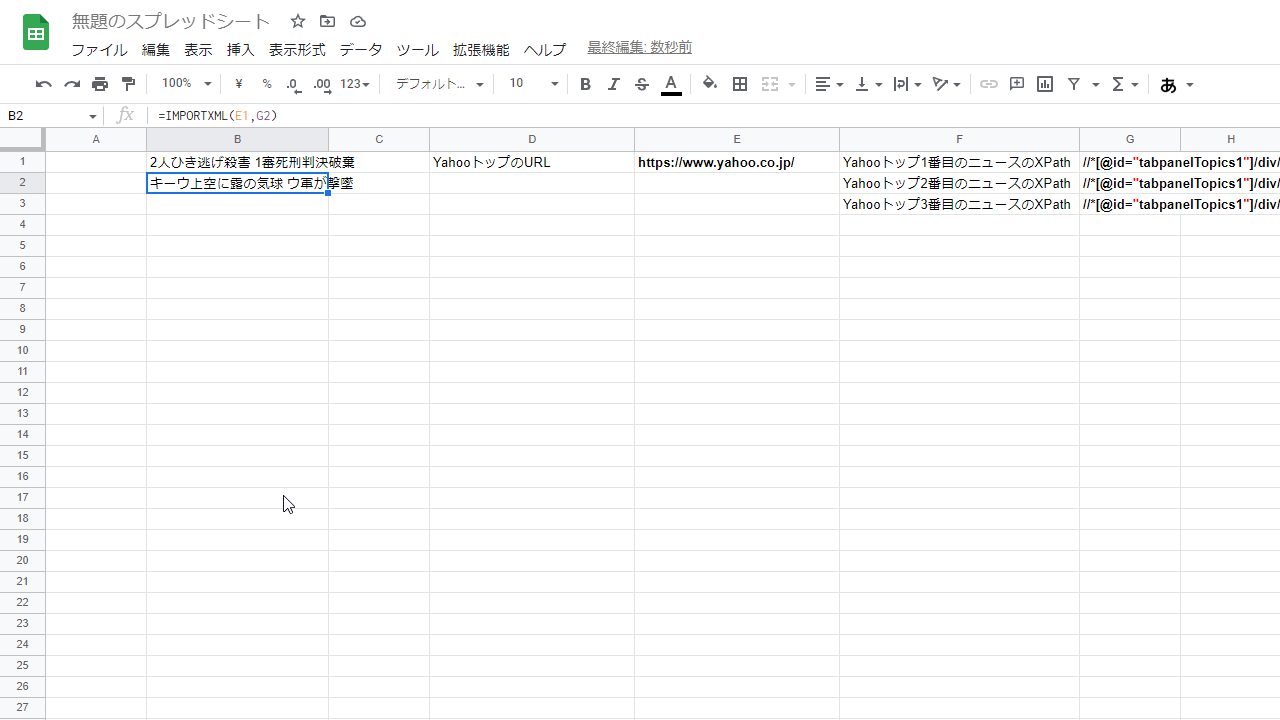
このように上から2番目のニュースが表示される。
(これもまた物騒なニュース…。)
覚えておいて欲しいこと
=IMPORTXML(“任意のURL”,”任意のXPath”)
この形式が基本となるが、上記の形式はURLもXPathも直接入力する場合。先程のように事前にURLが入力されているセルを指定してやる場合は、ダブルクォーテーションは不要となる。
また直接入力の場合は、XPath内にダブルクォーテーションが含まれていないか確認すること。
(→含まれている場合はXPath側のダブルクォーテーションをシングルクォーテーションに変更すること)
その辺りを確認しておかないと、エラー吐いて1時間~2時間くらい苦戦することになるかもしれない。ちなみに筆者は苦戦した経験アリ。
なおサイトによってはこうしたデータを勝手に読み込んでもらう行為(スクレイピング)を禁止しているサイトも存在する。Amazonなども無許可でのスクレイピングは禁止されている。
スクレイピング行為は、数件~数十件程度ならまだしも、数万件単位*何千人単位での利用となると、サイト側に膨大な負荷がかかるため、特に意味もなくスクレイピングするのはやめようね。
あとこれは本当に余談であるが、今までIMPORTXMLと記述してきたが、別にimportxml(小文字)でも問題ない。
=SuMとかでもSUM関数は動くし、=VlOoKuPとかでもちゃんとVLOOKUP関数は動く。
本題 佐川急便の配達状況XPath
というわけで、本題に入る。
佐川急便の赤丸の部分のXPathを調べる。
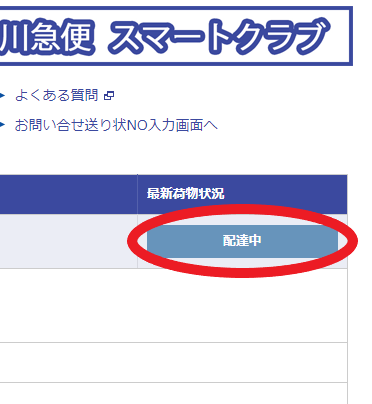
調べ方は至って簡単で、ページを開いた状態でF12キーを押してデベロッパーツールを開く。
※ページ内で右クリックして検証とか調査を押しても開ける。Macとかも同じ感じじゃないのしらんけど。
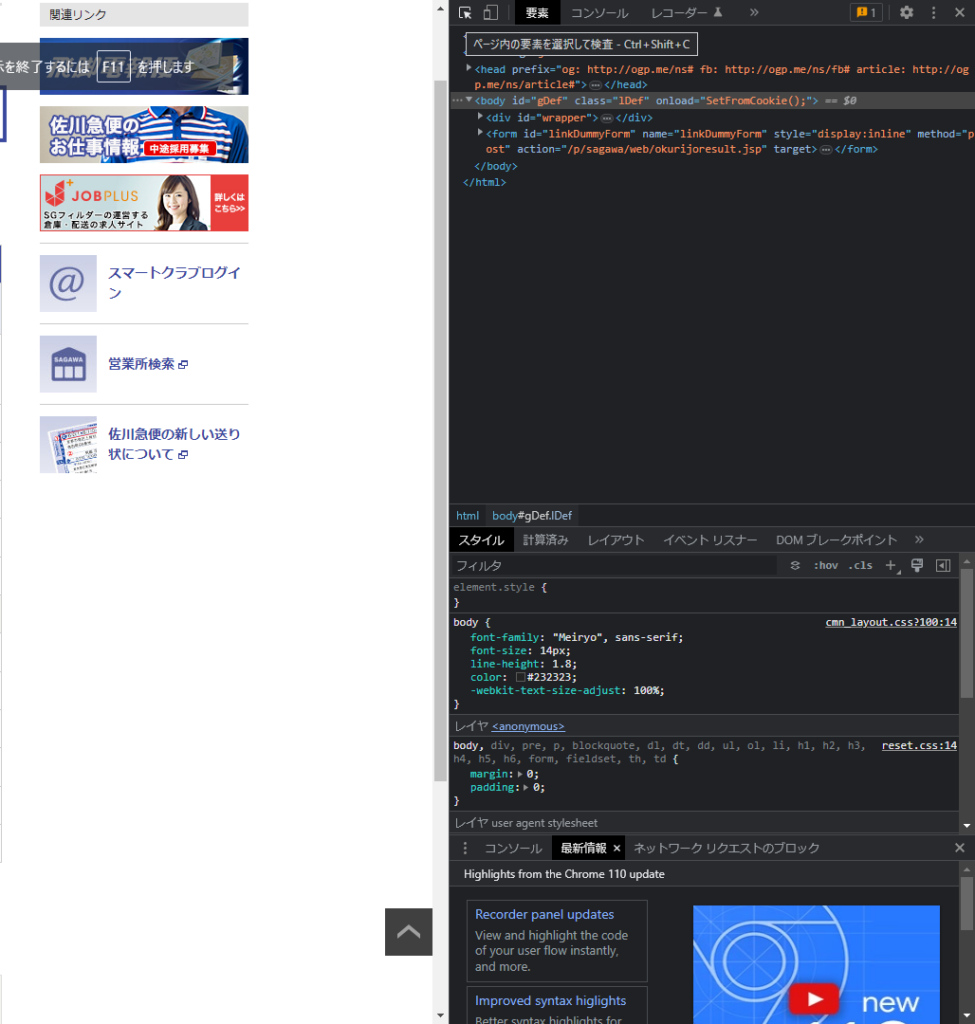
すると画面の右側になにやら面倒くさそうなモノが出てくるが、そこまで面倒なことはしない。
デベロッパーツールの左上にあるカーソルみたいなマーク(①)を押したあとに、最新荷物状況の下に表示されている文字(②)を押す。
※このケースの場合、②は配達中と表示されている部分を押す。
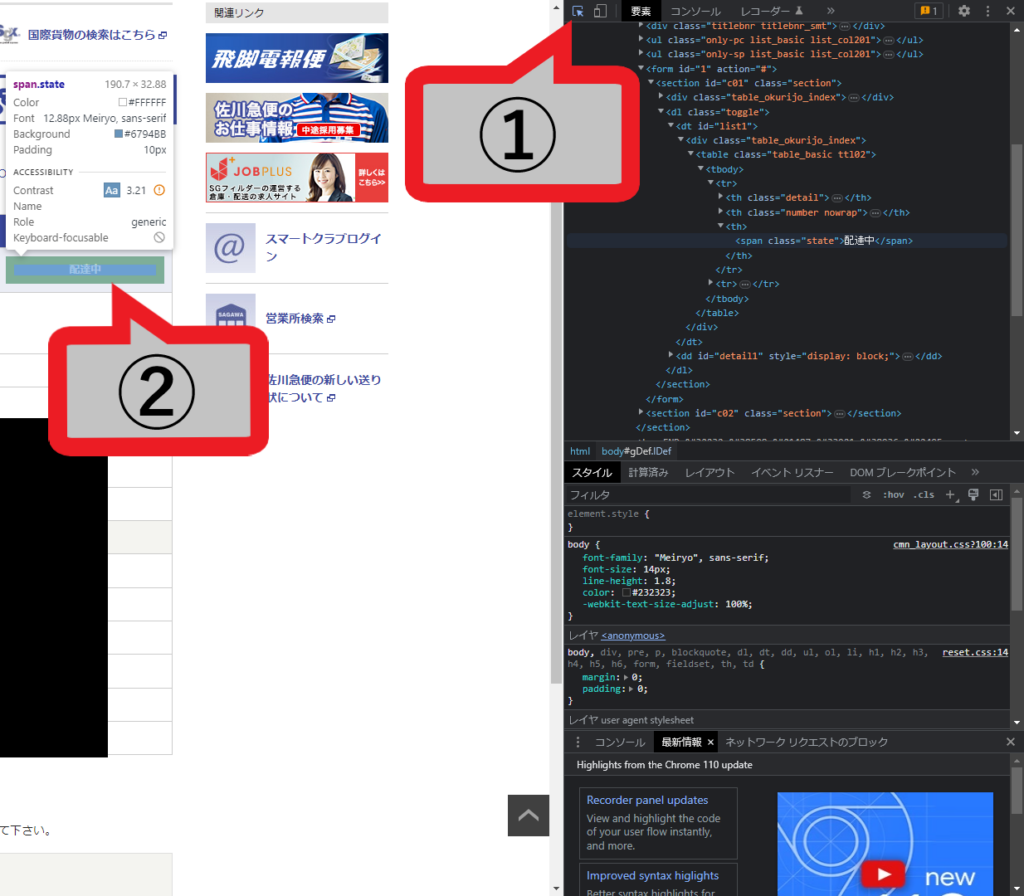
上記の操作が完了したら、デベロッパーツール側では②で選択した要素が横一列、薄いハイライトで強調されていると思う。
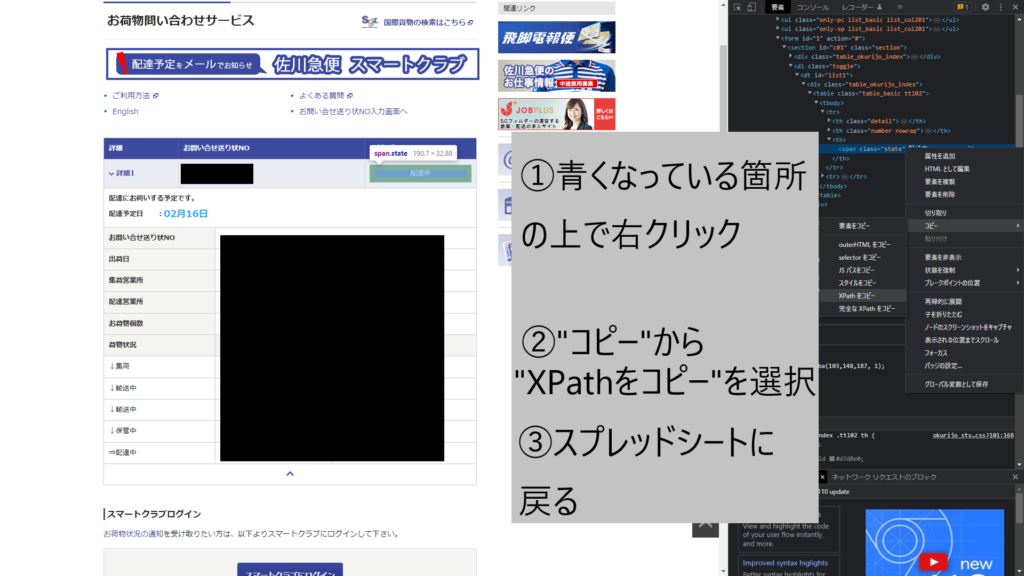
そのハイライトの上で、右クリック>コピー>XPathをコピーの順に操作。この操作も終わったら今度はスプレッドシートへ戻る。
スプレッドシートをいじる
とりあえず、先程コピーしたXPathを適当な場所にペースト(貼り付け)しておくことを推奨。
今回はE3セルにペーストしておいた。
まずはURLもXPathも直接入力したケースで進める。
URLはhttps://k2k.sagawa-exp.co.jp/p/web/okurijosearch.do?oku01に追跡番号(12桁)を足したモノとなるため、
https://k2k.sagawa-exp.co.jp/p/web/okurijosearch.do?oku01=123456789012 となる。
次に取得したXPathを確認する。
//*[@id=“list1“]/div/table/tbody/tr[1]/th[3]/span
親方!!XPathにダブルクォーテーションが含まれています!!!
XPathにダブルクォーテーションが含まれているため、当該箇所をシングルクォーテーションに書き換える。
//*[@id=‘list1‘]/div/table/tbody/tr[1]/th[3]/span
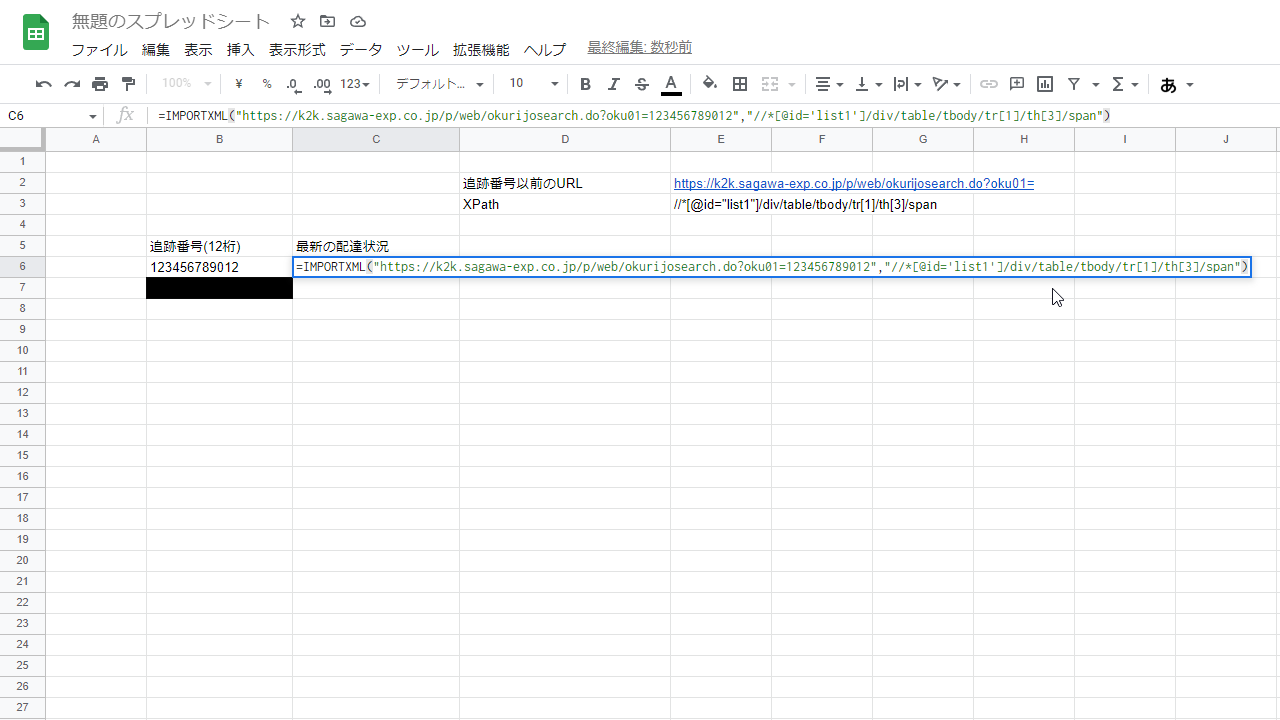
これで準備が完了。最終的には
=IMPORTXML("https://k2k.sagawa-exp.co.jp/p/web/okurijosearch.do?oku01=123456789012","//*[@id='list1']/div/table/tbody/tr[1]/th[3]/span")となる。
これをC6セルに記述してエンター。すると、
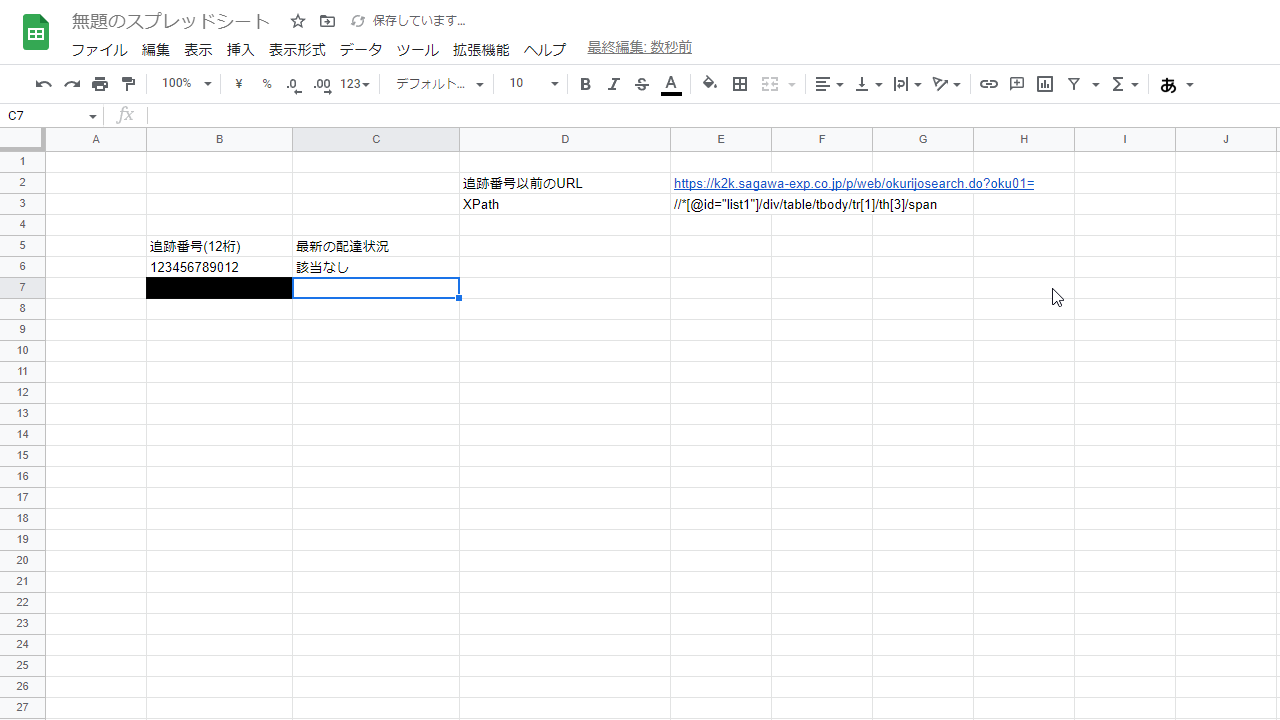
無事該当なしと表示された。今回は存在しない追跡番号を入力したため該当なしと表示されている。
次は実際に存在する追跡番号で応用してみる。
セルの指定及び文字列を結合させる
E2セルに追跡番号より手前のURL、E3セルにXPathを入力しておいた。
先程の項目でも説明した通り、セルを指定する形式の場合、ダブルクォーテーションは不要となる。
とはいえ、いちいち追跡番号を入力したURLを準備するのは面倒。というわけで、今回はB列に記入されている追跡番号とE2に記入されているURLを結合させる。
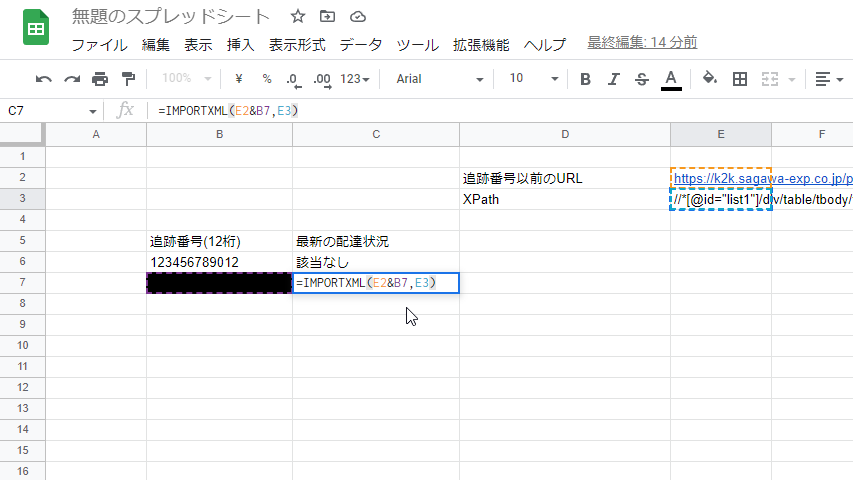
やり方は非常にシンプル。上記セルの場合、=IMPORTXML(E2&B7,E3)と入力するだけ。
今回はB7に入力されている追跡番号の配達状況を知りたいため、C7に上記の内容を記入する。
E2セルにはURL、B7には追跡番号が入力されている。
E2(https://k2k.sagawa-exp.co.jp/p/web/okurijosearch.do?oku01=)とB7(追跡番号)を結合させて一つの文字列にしてしまおうってことで、E2とB7の間に&という記号を挟んでいる。こうすることで、追跡番号をB列に入力するだけで勝手にデータを抽出してくれる。
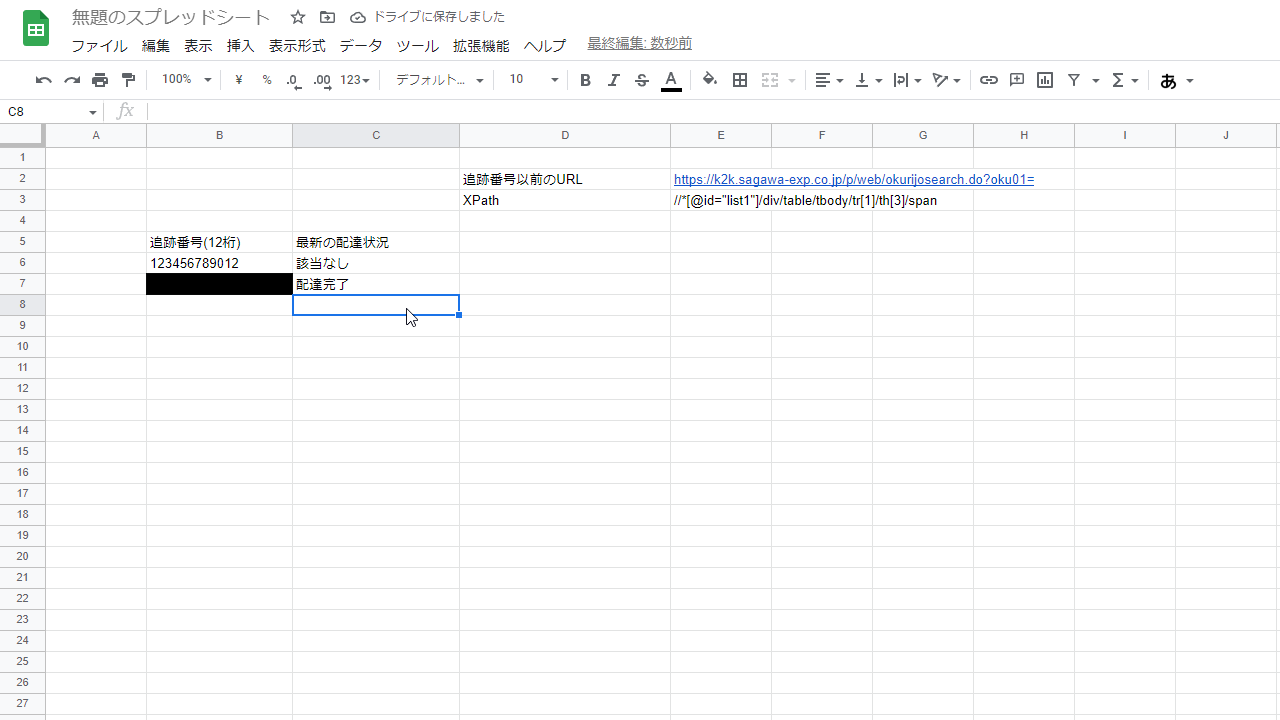
するとこのように、C7 最新の配達状況が更新され、配達完了となった。
なおC7に=IMPORTXML(E2&B7,E3)と入力したままオートフィル(カーソル右下の四角をグイッと下の方にやったりするアレ)をすると盛大にエラーを吐く。
上記シートの状態でC7より下も同じように追跡番号の最新の配達状況を知りたい場合は、
=IMPORTXML($E$2&B7,$E$3)と、E2とE3を絶対参照にしてから記述してからオートフィルをするとよい。
総括
意外と簡単。※ただし難アリ。
長々と記述したが、実際に操作すれば初めてでも5分~10分程度で終わると思われる。ただしこのIMPORTXMLはやや癖があることを忘れてはならない。
まずIMPORTXML関数は、いつでもリアルタイム更新というわけではない。
データの更新頻度
使用量が適切に維持されている間はユーザーが最新のデータを取得できるようにするために、IMPORTDATA、IMPORTHTML、IMPORTXML では複数のルールを共有しています。ユーザーがドキュメントを開いている間、この 3 つの関数は 1 時間ごとに自動的に更新を確認します。数式とシートが変更されていない場合でも、確認します。
https://support.google.com/docs/answer/12188454?hl=ja
ユーザーがセルを削除してもう一度追加した場合や、同じ数式でセルを上書きした場合、これらの関数は更新をトリガーします。
更新は基本的に1時間ごと。またシートを開いている間に限る。セルを消したり上書きした場合はこの限りではない。
(つまるところシートを開いていない間は恐らく更新されず、次回開いたときに更新される)。
GASを用いて強制的に更新するのでれば別だが、初めての人には敷居が高い。
(でも調べりゃそんな感じのことしてる人たくさん出てくるはず)
またIMPORTXML関数を多用すると、スプレッドシートが非常に重くなりがち。
1つや2つ程度なら問題ないのだが、50とか100とか使い始めると相当重くなる。まあ外部サイトにアクセスしてデータ拾ってきて書き出してなんて操作を勝手にやってくれるんだから、そりゃ重くなるわな。
結局のところGAS使えよって話なのだが、やはり敷居は高め。慣れないうちはできる範囲のことに全力を尽くしておけば良し。大体のことは力技でどうにかなっちゃうんだから。

コメント